
An Alternative to Transformers: State Space Models
An overview of sequence modelling and state space models


Transformers have literally been getting all the attention in recent years thanks to their exceptional performance in modelling sequences especially language. Large sums have been poured into developing infrastructure to train and run these models at increasing scale, lower latency and lower costs. This is not just software, but also hardware. Whilst transformers are incredibly performant they have inherent scaling limitations that place constraints on inference speeds and context window sizes. Consequently, the research world is beginning to explore new advancements, for example, some months ago, Google announced a Diffusion model for text. Research teams are branching in all sorts of directions and AI Researcher Sebastian Raschka has documented some of these in his latest blog post.
The innovation I want to talk about in this post is State Space Models (SSMs). A couple of years back, researchers at Stanford introduced State Space Models (SSMs) which landed with some initial buzz but which soon dissipated. However, those same researchers have been showing the world just what these models can do recently by releasing a new voice generation model via their company Cartesia. Their models are fast with 90ms model latency and 190ms end-to-end latency. This caught my attention and so I thought it was about time I dove deeper into SSMs to understand how they worked.
In this post, I hope to give a flavour of the current state of sequence modelling with transformers, describe the main ideas behind SSMs and compare the two architectures. I have left a lot of the technical details out — you should read posts from the real experts. Finally, this post is also as much for me to test my understanding. If there’s anything that is wrong or unclear please shout. I’m receptive to feedback.
A history of modelling language and sequences
The transformer model is at the heart of the recent wave of generative AI models. Invented in 2017, transformers have become ubiquitous in sequence modelling tasks involving text i.e. language modelling, but have also proven effective in modelling other modalities such as image, audio and even DNA modelling.
Transformers took off because they were a new class of model that overcame the limitations of the previous generation of models used for sequence modelling, Recurrent Neural Networks (RNNs). Sequences are composed of a collection of items or tokens, as they’re more commonly known today. A sequence can be a body of text and tokens could be characters, words or even a mix.
RNNs process a sequence by ingesting and processing each token one at a time. As they do so, they maintain information about the sequence semantics and token relationships in something called a ‘state’. This state is then updated as each new token is processed. It’s somewhat analogous to what happens in conversation: we listen to each word spoken to us and condense that into a summary of sorts capturing the entire meaning of the message. Below is a diagram from Chris Olah’s excellent technical post on RNNs which shows the input tokens (x) being processed one at a time to produce the output (h). In each step, the state (A) is being updated using the past steps state and the new token information.
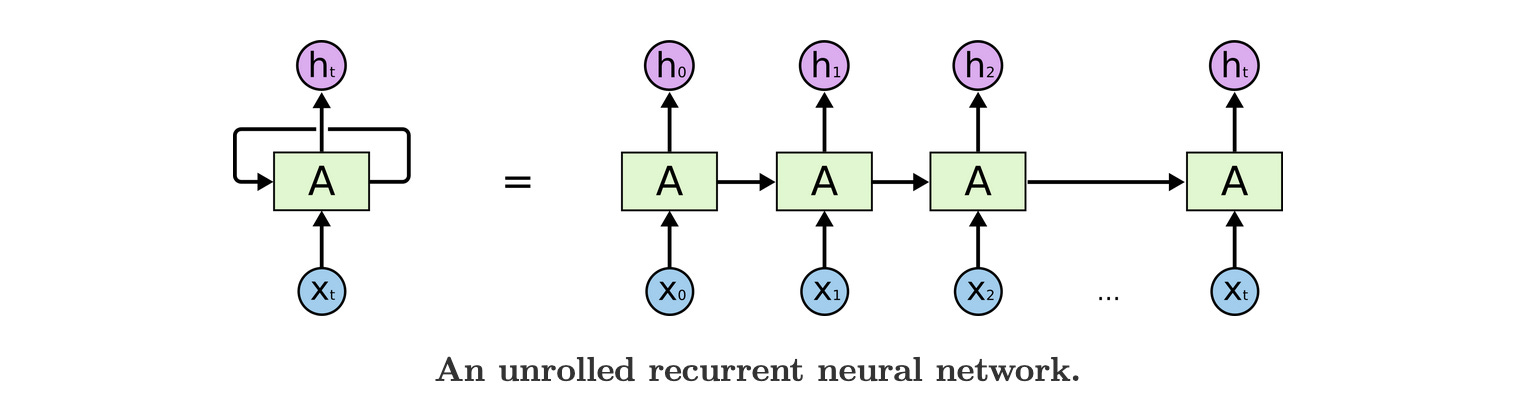
RNNs and their many variants moved the field along significantly but were bottlenecked by the sequential nature in which they processed information. This wasn’t conducive to parallelisation and hence couldn’t take advantage of the capabilities of GPUs, which placed constraints on our ability to train larger and larger models. And as we’ve seen, performance has been greatly tied to scale. The transformer eliminated this bottleneck processing a sequence all in one go. They are able to understand the sequence semantics and token relationship using the idea of self-attention.
The Transformer’s Attention Mechanism
Unlike recurrent models, transformers do not process a sequence token by token nor do they keep a running state like RNNs. Instead, transformers compare each token to every other token to determine their relationship and impact on the overall meaning of the sequence. This mechanism is called self-attention. The transformer then learns to understand the strength of each pairwise relationship, shown in the illustration below by the colour scale.
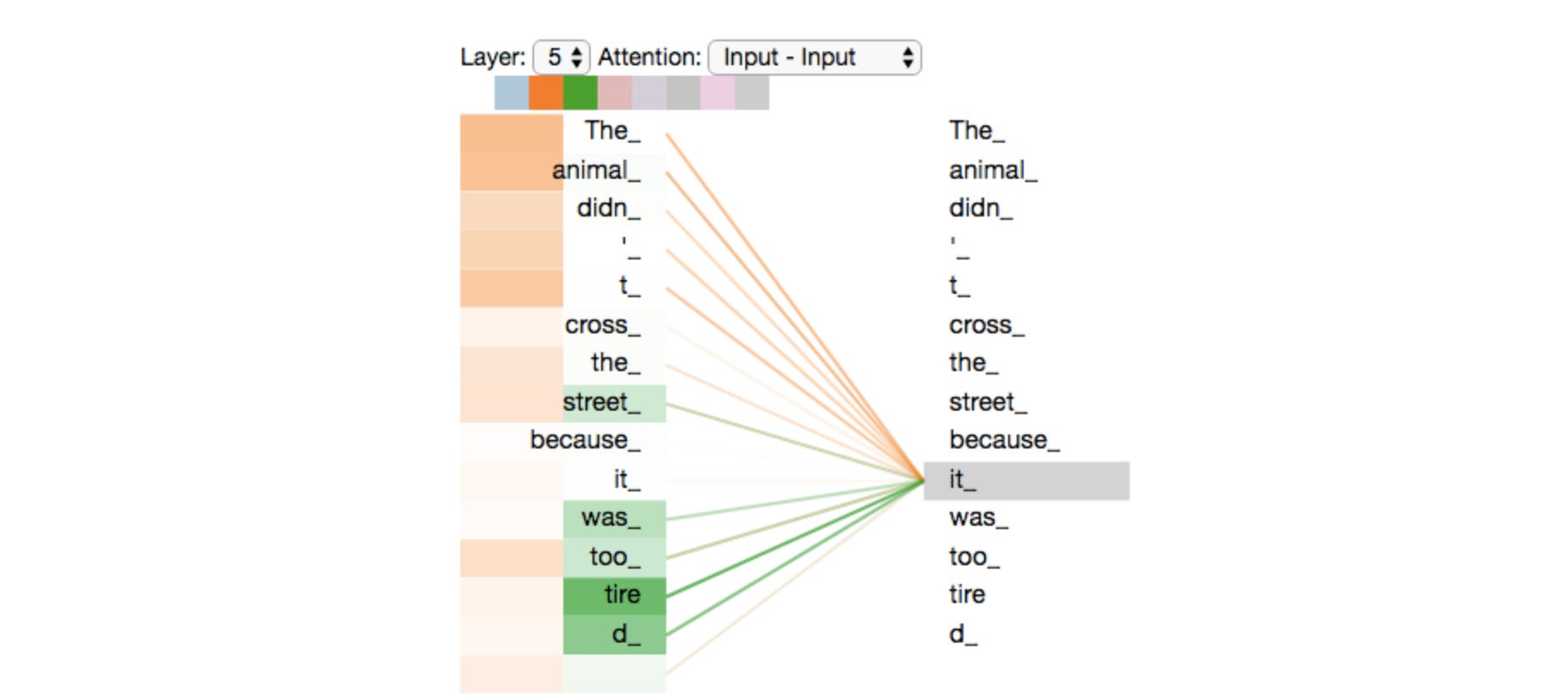
With the sequential processing bottleneck out of the way, the operations in a transformer could be massively parallelised, increasing efficiency and opening the doors to a world of ultra-large models that have yielded significant performance improvements on modelling sequences. Ironically though, this very innovation that has helped the transformer flourish is also the constraint that is fuelling its successor. This is because the pairwise comparison step, scales quadratically. In other words, for a sequence of length N, the model must compute N^2 relationships: every token attends to every other token, including itself.
This is really computationally expensive impacting how quickly a transformer can process longer and longer sequences. On top of that, as transformers process a sequence all at once, the memory requirements grow with sequence length and become prohibitive. This is part of the reason why context window sizes are capped. These limitations are well-known and a lot of manpower and funding has been spent on increasing the overall efficiency of the transformer and self-attention. At the end of the day, there are great incentives to lower latency and cost to ensure AI can remain commercially viable and accessible. Teams have made adjustments to many parts of the architecture and hardware has increasingly been optimised to run these large models more efficiently (e.g. flash attention, research into more scalable infrastructure). One commonly used technique is caching. When LLMs are run at inference time, they output one token at a time by processing the input sequence, generate the next token, append that to the sequence and run the new sequence through the model again. This is a bit wasteful because most of the pairwise calculations do not need to be recalculated. The only new information that requires computing is the interaction between the new token and the sequence. So teams now save these computations trading memory for decreased latency. The time to generate the first token remains expensive but subsequent tokens can be generated much faster. This is why the industry tracks time-to-first-token (TTFT) and tokens per second separately.
Yet, even with all these innovations, transformers still face this limitation with attention speed and storage, which stands in the way of real-time AI and processing longer and longer contexts. And so finally, after a not-so-brief introduction, we can talk about State Space Models (SSMs).
State Space Models
SSMs have existed for some time outside the domain of AI but were only applied in AI contexts a few years ago with pioneering work from Stanford. These researchers went on to found Cartesia leveraging the these models to generate audio close to real-time. So how do SSMs work and what makes them fast relative to transformers?
Vanilla SSMs
Like recurrent models, SSMs operate on the principle of maintaining a state and they process each input token one step at a time. The main difference is that SSMs evolve the state linearly whereas RNNs use non-linear transformations (SSMs vs. RNNs — link). Below is a set of equations that describe the operations of a vanilla SSM at each step.
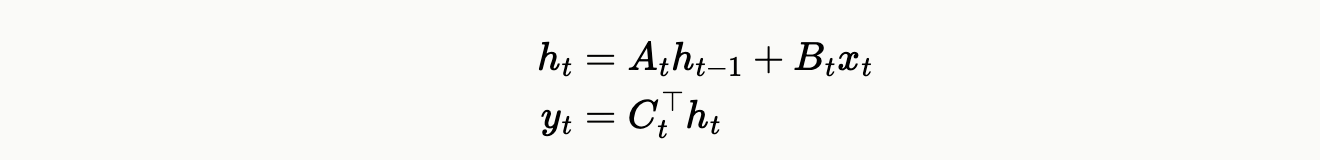
Here the state is represented by h, the input x, and the output y. A, B and C transform the input and state, and parameters of the model that are learned through training. As we mentioned earlier, the advantage of these state-based models is that they compress information about the sequence into a single vector and they process one token at a time. So memory requirements are fixed in size and the computation grows linearly with sequence length. Transformers keep everything in memory but pay quadratically in computation
Having said all this, these vanilla SSMs couldn’t match the performance of transformers because 1) their fixed-sized state wasn’t expressive enough to model all the interactions in complex sequences, and 2) compressing context destroyed information which couldn’t be easily retrieved so they suffered on tasks like selectively copying information e.g. numbers from a phonebook. Transformers are excellent at this because they have the whole sequence in memory and can copy across the relevant tokens to the output.
Enter Mamba
Hopefully this is obvious, but the effectiveness of these state-based systems is the state and the ability to manage its evolution, and here A and B are the parameters that critically control how this is done. In the vanilla implementation, the parameters are independent of the inputs and so they cannot adjust the state in a variable way based on the input. Step in Mamba, which introduced these changes and saw marked improvement. Of course there’s no free lunch, and this change made computation less amenable to parallelisation. To compensate, Mamba also introduces neat tricks that take advantage of hardware to parallelise. You can read more about them in this post.
With these changes, the researchers found that Mamba was comparable if not better than most competing model architectures including transformers on a range of sequence modelling tasks.
Future
So where does this all leave us? Interest seems to be blossoming around SSMs. Their linear scaling and the compressed state forces information into a fixed-sized memory that is an appealing avenue towards fast, cost-efficient, real-time AI systems. This could be advantageous for on-device computing where memory is constrained. Also in the domain of audio where Cartesia operates, SSMs might lead to higher quality generations. This is because audio is a continuous signal that is often sampled to be processed digitally. Assuming audio data is represented by a sequence of individual data points separated by a time interval set by the sample rate, an SSM might be able to process much longer sequences at higher sample rate than a transformer because of the aforementioned limitations.
If there are so many positives, why haven’t more teams begun implementing SSMs? Well there are teams that exploring hybrids models which can take advantage of the linear properties of SSMs and the copying or ‘lookup’ properties of transformers. Earlier in the year IBM launched a small hybrid model called Bamba achieving 2x latency speedup over a standard transformer. These variants might be more common.
However, it’s also not easy for large players who have optimised their infrastructure for transformers to suddenly shift to SSMs. Further, a lot of the public research and results comparing SSMs to transformers has so far been on small scale models hovering around the 7B parameters. Maybe SSMs don’t maintain or improve performance at scale in the same way transformers do, which today are 50-100x in size.
In summary though, the state of play is shifting, and it will be exciting to see how our algorithms and models develop over the coming years.